Gallery
About
A friend and I built a browser prototype that answers questions about whatever’s on your screen using getDisplayMedia, client-side wake-word detection, and server-side multimodal inference.Hard parts:– Getting the model to point to specific UI elements– Keeping it coherent across multi-step workflows (“Help me create a sword in Tinkercad”)– Preventing the infinite mirror effect and confusion between window vs full-screen sharing– Keeping voice → screenshot → inference → voice latency low enough to feel conversationalWe packaged it as “Clippy” for fun, but the real experiment is letting a model tool-call fresh screenshots to help it gather more context.One practical use case is remote tech support — I'm sending this to my mom next time she calls instead of screen sharing.Curious what breaks.
Comments (1)
what multimodal model are you running server side?
Related Products

Free Currency Converter API

Limestone Digital
AI-Powered Software Development, Engineering Team Augmentation,

ChangeSpec
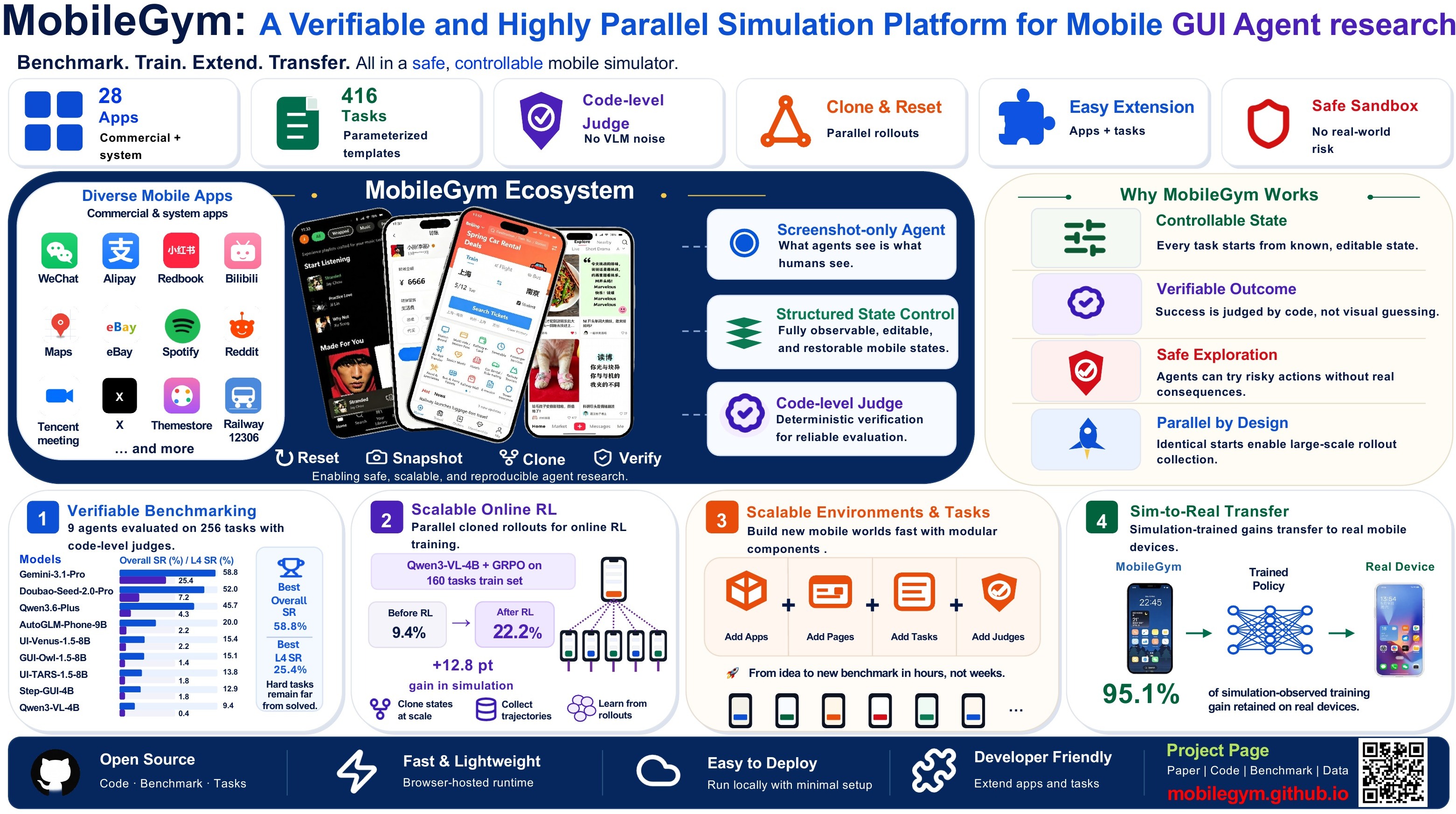
MobileGym: A Verifiable and Highly Parallel Simulation Platform for Mobile GUI A
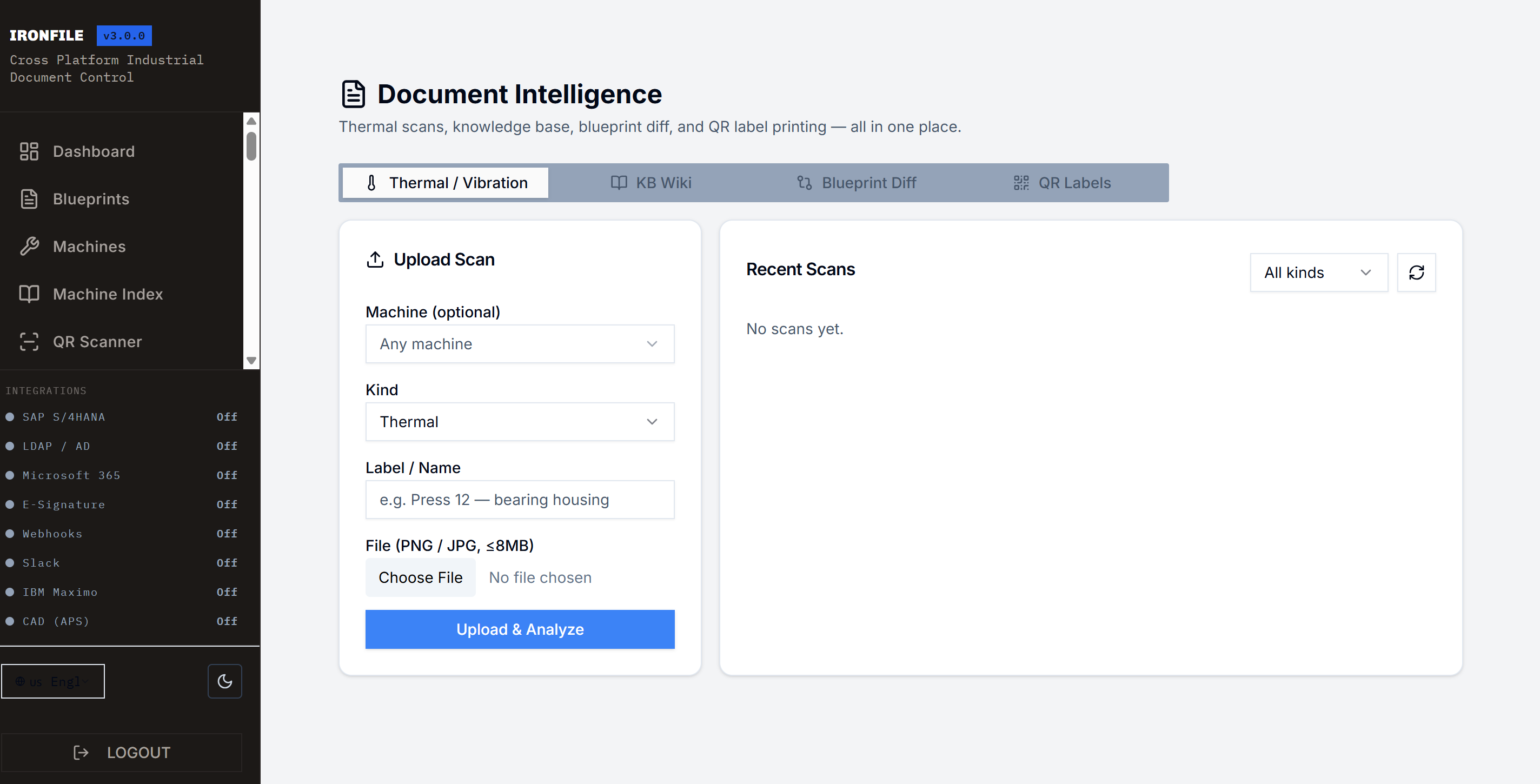
IronFile - Completely Customizable
Turnkey Industrial SaaS Platform (80k+ LOC) • 12 Enterprise Connectors
Technologies.lat
Quality Assurance for software that is here for the long run