Metal Quantized Attention: pulling M5 Max ahead with Int8 matrix multiplication
Apr 1, 2026
AI & Machine Learning
attention mechanisms
neural networks
quantization
Gallery
About
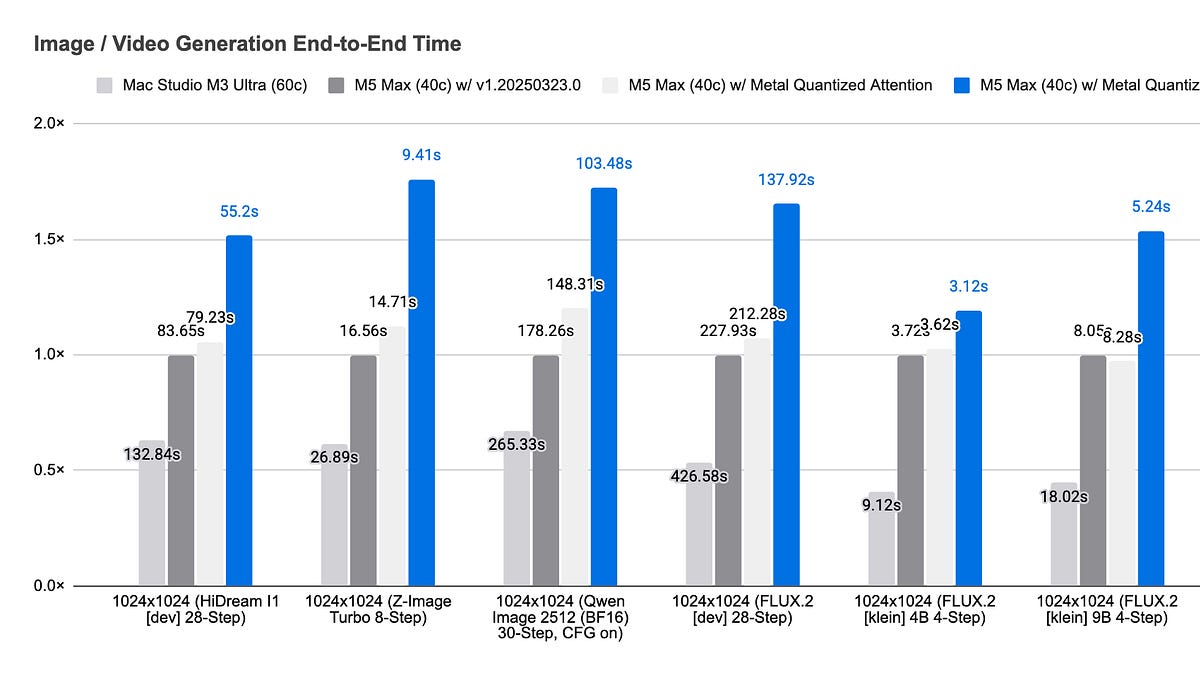
Metal Quantized Attention on M5 Max is a machine learning model optimized for Apple's M5 Max chip, enabling efficient processing of attention-based neural networks. This model leverages quantization to reduce memory usage and improve inference speed. It is designed for use cases that require low-latency and low-power consumption, such as real-time image and video processing.
Comments (0)
No comments yet. Be the first to comment!
Related Products
Typist
Transcribe audio to text in seconds.

rapym
TKCORE AI
All-in-one AI platform featuring TkCore-V5.5-Pro & top LLMs
A
ai image prompts
Copy-paste AI image prompts that actually work.
ChatFlow
AI chatbot for your website — live in minutes
Trygnt - Marketplace
Marketplace for selling and purchasing AI Agents